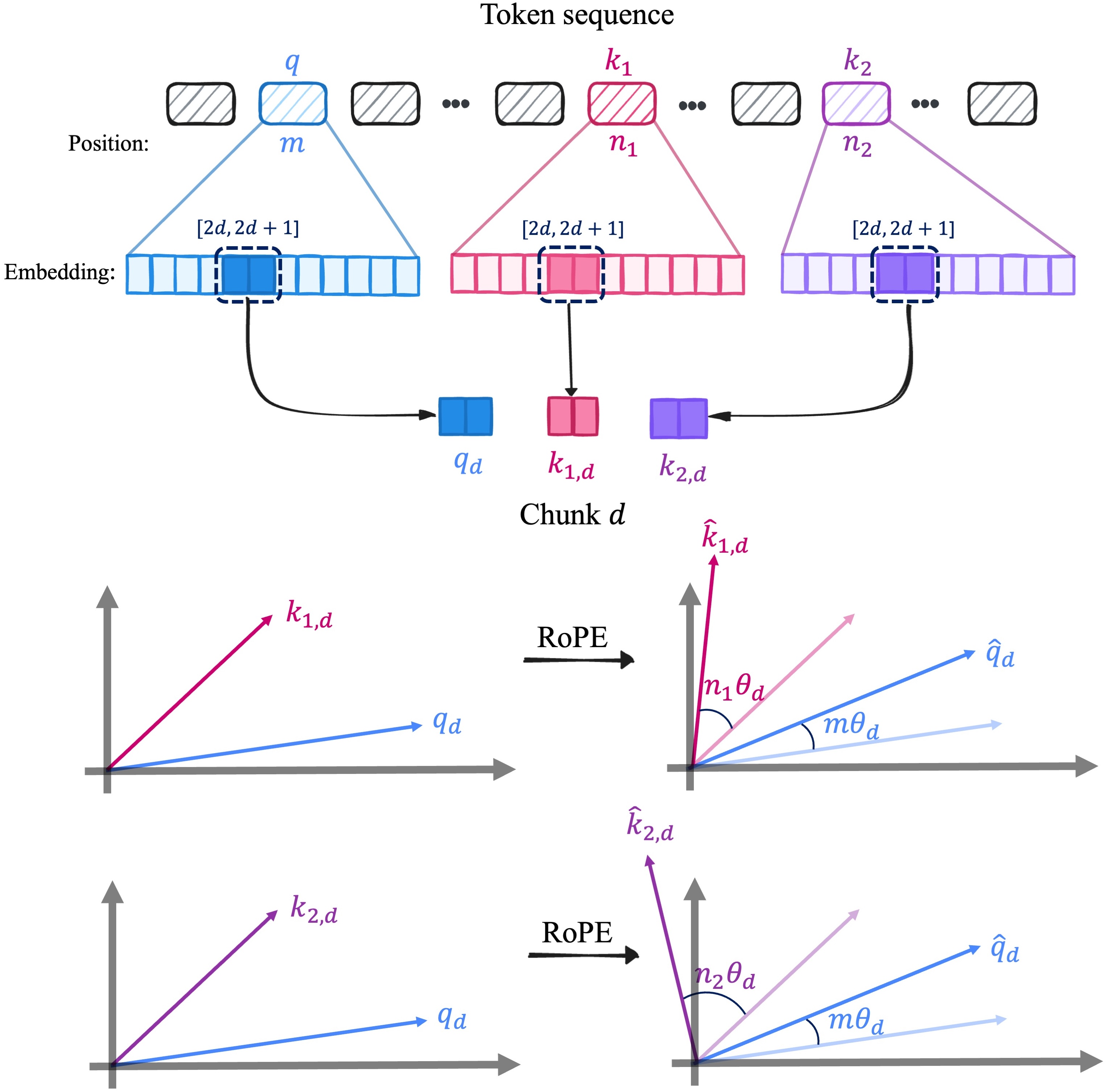
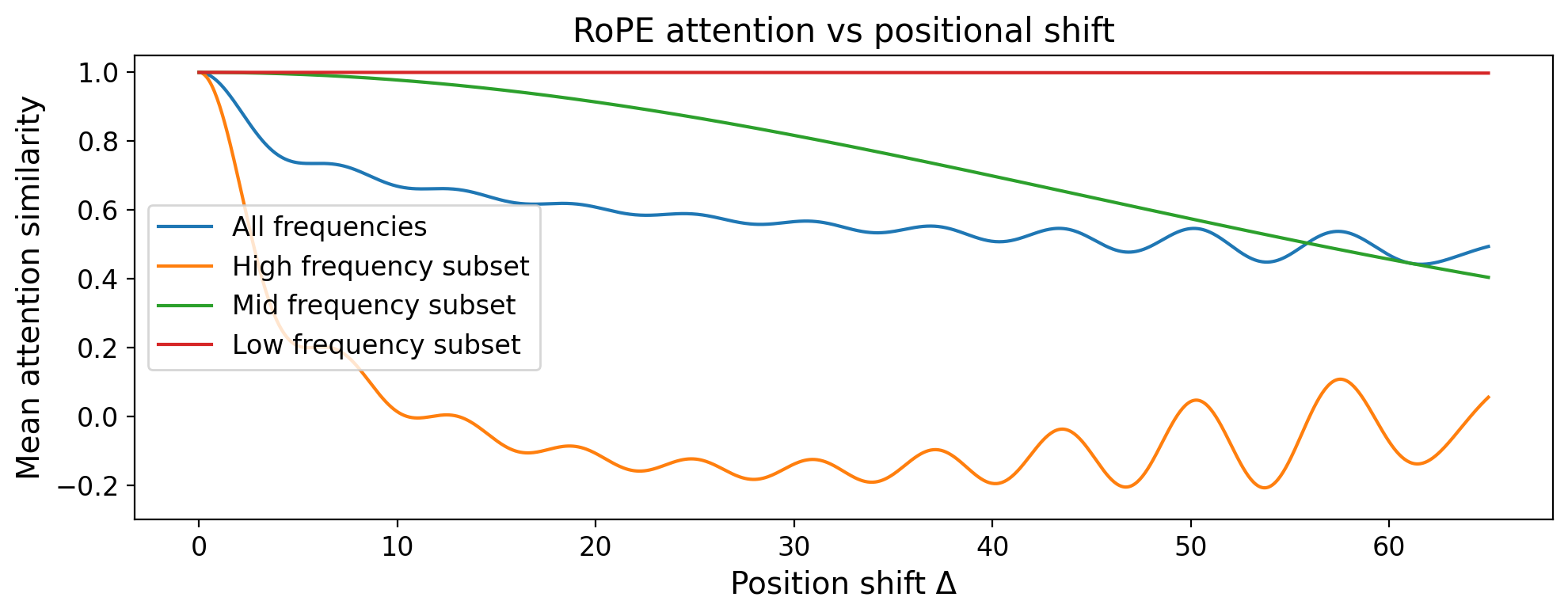
TL;DR: Shared attention in RoPE-based diffusion transformers often collapses into reference copying, reproducing the reference image instead of transferring its style. We trace this back to RoPE's high-frequency components and introduce a simple, training-free frequency-aware modulation that restores meaningful shared attention and enables controllable style-aligned generation.
Reference
The Cathedral of Santa Maria del Fiore
The Statue of Liberty
The Colosseum

Reference
Two knights playing chess
A man eating pizza
A clown dancing

Reference
A koala bear sitting on a tree
A wolf howling at the moon
A monkey swinging from a branch

Reference
A woman playing guitar
The Seattle Space Needle
A cat playing with a ball of yarn

Reference
A majestic lion
A beautiful butterfly
A scenic waterfall

Reference
The New York skyline
An ice skater performing a jump
A woman reading a book in a park

Reference
A marathon runner
A fruit basket on a table
Two kittens playing
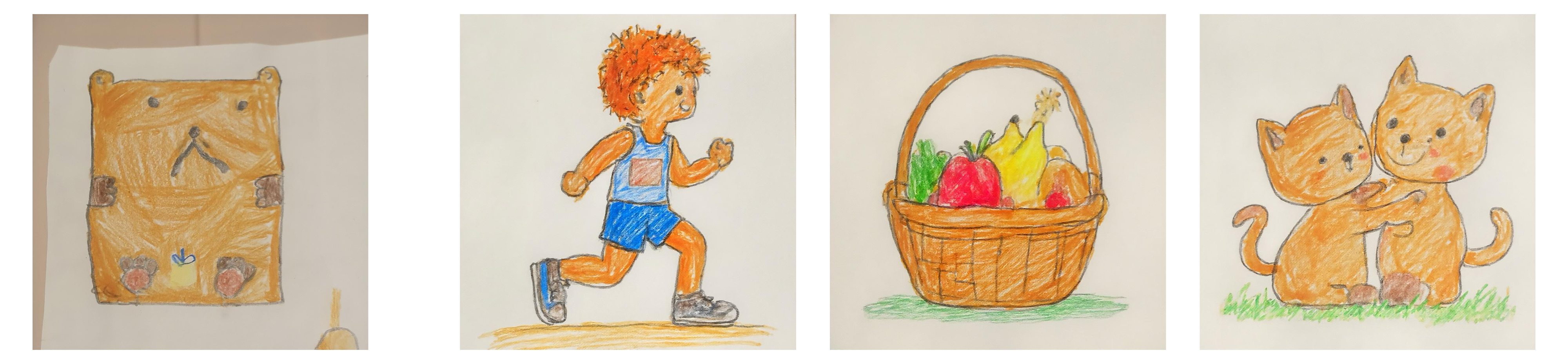
Reference
A bicycle
A seashell
A swan
Reference
A fireman
A wooden house
A gold chest

Reference
A pine tree
A pineapple
An eagle in flight

Reference
A dog catching a frisbee
A bear eating honey
A man riding a bicycle

Reference
A firefighter figurine
A doctor figurine
A police woman figurine

""